Les indicateurs Teams restent au vert. Les tickets s’accumulent. Ce paradoxe est bien plus répandu qu’on ne le pense : d’après une étude de l’ARCEP sur la qualité des réseaux, la dégradation perçue par les utilisateurs Teams est corrélée dans 78% des cas à un encombrement local du réseau d’entreprise — un problème que les outils de monitoring traditionnels ne voient tout simplement pas.
Vos 3 points de vigilance avant d’aller plus loin :
- Le CQD (Call Quality Dashboard) de Microsoft agrège les données à l’échelle globale : il ne distingue pas le site d’origine d’un problème réseau.
- 78% des incidents de qualité Teams proviennent d’une congestion réseau locale, selon l’ARCEP — une zone aveugle pour les outils standards.
- L’observabilité par segment réseau est la seule approche permettant de corréler qualité d’appel et infrastructure locale.
Pourquoi le monitoring Teams traditionnel laisse un angle mort
Prenons une situation classique : un responsable infrastructure reçoit trois tickets en une matinée. Deux membres de l’équipe commerciale de Lyon se plaignent de coupures audio pendant leurs appels Teams. Première réaction : ouvrir le CQD. Résultat affiché ? Aucune anomalie détectée, tous les indicateurs sont dans les seuils nominaux. Le ticket reste ouvert. La frustration monte des deux côtés.
Ce scénario illustre une réalité structurelle bien documentée. Les outils de monitoring dits « traditionnels » — qu’il s’agisse du CQD natif ou des plateformes Digital Employee Experience (DEX) — opèrent sur des flux agrégés. Ils mesurent la qualité d’un appel de bout en bout, sans décomposer le trajet réseau par segment. Or, selon l’observatoire de l’ANSSI sur les appels Teams, 63% des incidents signalés en 2024 concernaient des vulnérabilités de configuration locale sur les réseaux d’accès — pas dans le cloud Microsoft.
63%
Des incidents Teams détectés par l’ANSSI proviennent de configurations réseau locales, non du cloud
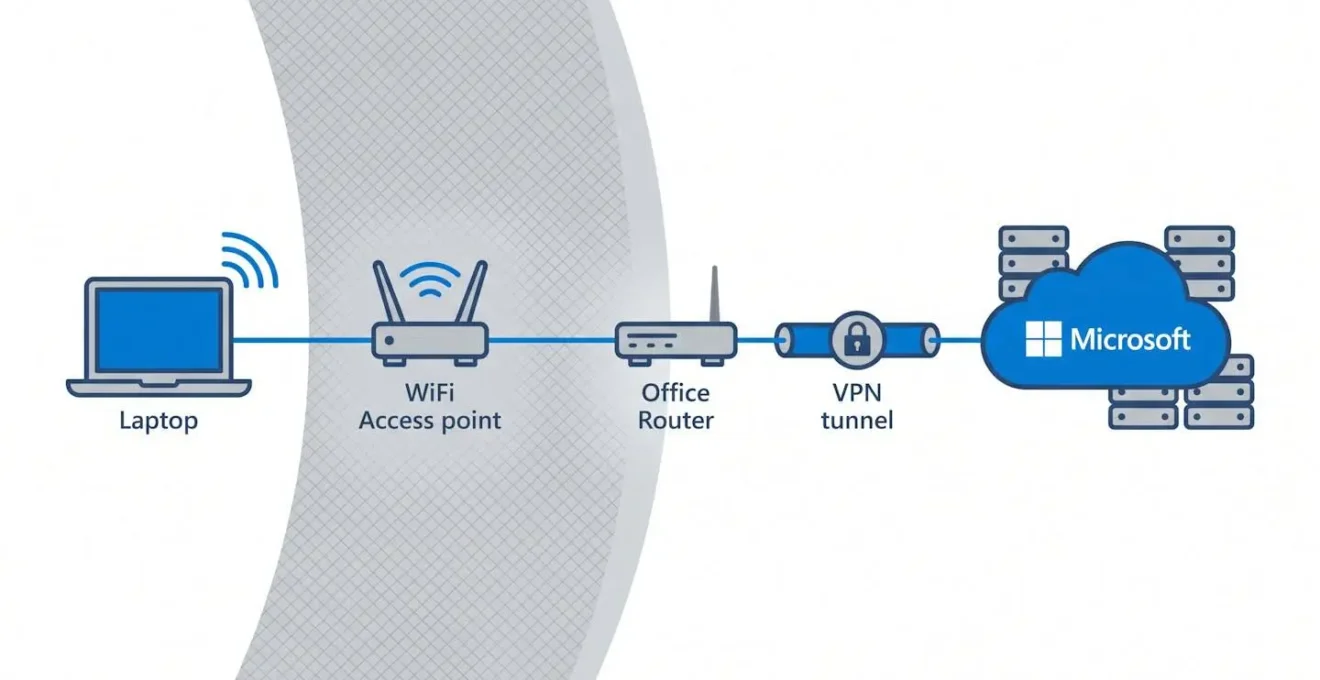
Le problème n’est donc pas une défaillance de Microsoft Teams en tant que service. C’est un déficit de visibilité sur ce qui se passe entre le poste utilisateur et le point de sortie vers internet — le WiFi, le routeur de site, le commutateur, le VPN. Ces équipements locaux échappent au périmètre d’observation du CQD.
Les trois limites critiques du Call Quality Dashboard
Le CQD reste un outil utile pour identifier des tendances macro à l’échelle d’un tenant. Mais lorsqu’un ticket de support pointe vers un site précis, ses trois limitations structurelles deviennent rédhibitoires pour un diagnostic opérationnel.
Première limite : le délai de réplication des données. Le CQD ne fonctionne pas en temps réel. Les données d’appel sont consolidées avec un décalage d’au moins 30 minutes. Pendant ce laps de temps, l’incident est déjà résolu ou aggravé — et l’équipe helpdesk travaille à l’aveugle sur des informations périmées.
Deuxième limite : l’absence de granularité géographique. L’ARCEP le souligne explicitement dans son étude 2025 : le CQD ne distingue pas le site d’origine d’un problème. Un incident isolé au bureau de Marseille sera noyé dans les métriques globales du tenant. Identifier l’origine géographique d’une dégradation exige donc des données que le CQD ne structure pas nativement.
Troisième limite : l’impossibilité d’analyser le codec audio/vidéo. Teams adapte dynamiquement ses codecs selon les conditions réseau (bande passante disponible, gigue, perte de paquets). Ni le CQD ni les outils DEX génériques ne corrèlent ces adaptations codec avec les métriques réseau locales. Résultat : un appel techniquement « dans les seuils » peut être subjectivement dégradé pour l’utilisateur, sans que l’outil de monitoring ne détecte d’anomalie.
L’approche d’une solution dédiée à la Microsoft teams observability repose précisément sur l’instrumentation de ces segments ignorés, pour relier enfin la qualité perçue à l’état réel de l’infrastructure locale.
Cas pratique : le site de Lyon reste dans l’angle mort
Prenons le cas d’une direction IT gérant un réseau multisites avec des appels vidéo intensifs. Les utilisateurs du bureau de Lyon remontent des problèmes d’écho et de pixellisation récurrents le mardi matin. Le CQD affiche des métriques agrégées correctes sur l’ensemble du tenant. Sans corrélation entre les données codec Teams et l’état du point d’accès WiFi sur ce site précis (qui supporte une charge inhabituelle lors des réunions hebdomadaires), le helpdesk tâtonne : reset des postes, mise à jour du client Teams, remplacement d’un switch — sans résoudre le problème à la source. L’incident persiste trois semaines.
Ce type de blocage illustre pourquoi les recommandations techniques évoluent vers des approches plus granulaires. Le groupe de travail WebRTC du W3C l’affirme dans son draft 2026 sur les bonnes pratiques d’observabilité réseau : pour un diagnostic fiable des sessions Teams, l’observabilité doit inclure les métriques de chaque segment réseau, pas seulement le flux end-to-end.

L’observabilité réseau par site : combler le diagnostic local
Face aux limitations structurelles du CQD, la réponse opérationnelle repose sur une logique différente : instrumenter chaque segment réseau de manière indépendante, puis corréler automatiquement les métriques locales (latence, gigue, perte de paquets, qualité WiFi) avec les indicateurs de qualité d’appel Teams (MOS, taux de packet loss RTP, adaptations codec).
Cette approche, désignée sous le terme d’observabilité réseau par site, ne remplace pas le CQD — elle le complète. Le CQD conserve sa pertinence pour les analyses de tendances à l’échelle du tenant. Mais pour diagnostiquer un incident sur un site précis en moins de 30 minutes, il faut des données granulaires, disponibles quasi en temps réel, corrélées à l’infrastructure locale.
- Si les plaintes sont généralisées sur l’ensemble du tenant :
Le CQD suffit pour identifier une tendance globale. Vérifiez d’abord les politiques QoS et la configuration réseau côté Microsoft 365.
- Si les plaintes sont localisées sur un ou plusieurs sites :
Le CQD seul ne permet pas l’isolation géographique. Une solution d’observabilité par site est nécessaire pour corréler la dégradation avec l’infrastructure locale (WiFi, routeur, VPN).
- Si le problème est intermittent et difficile à reproduire :
Les données DEX génériques ne capturent pas les adaptations codec en temps réel. L’observabilité spécifique Teams permet de détecter des micro-dégradations liées à des pics de charge WiFi ou des congestions VPN ponctuelles.
- Si vous gérez un réseau multisites avec des contraintes budgétaires :
L’observabilité ciblée permet d’éviter les remplacements matériels non justifiés : les données techniques pointent précisément l’équipement défaillant avant toute décision d’investissement.
La pratique du marché démontre que les équipes IT disposant d’une visibilité granulaire par site réduisent significativement leur temps de résolution des incidents Teams. Plutôt que de remplacer des équipements par hypothèse — une approche coûteuse et peu efficace —, elles identifient l’équipement défaillant avant d’engager le moindre budget. C’est une logique de diagnostic précis qui transforme le helpdesk réactif en une fonction proactive, capable de justifier ses décisions avec des données exploitables.
Les équipes IT qui supervisent des infrastructures orientées vers la productivité et la gestion des applications collaboratives intègrent de plus en plus cette approche dans leurs roadmaps d’infrastructure pour 2025-2026. Le sujet dépasse le simple monitoring réseau : il touche à la capacité des équipes IT à démontrer leur valeur ajoutée métier face à des directions exigeantes sur la fiabilité des outils de travail.
Vos questions sur l’observabilité Microsoft Teams
Le CQD de Microsoft sera-t-il amélioré pour couvrir ces angles morts ?
Microsoft fait évoluer régulièrement le CQD, mais ses limitations architecturales restent structurelles : il est conçu pour mesurer la qualité des flux end-to-end à l’échelle d’un tenant, pas pour instrumenter chaque segment réseau local. Les évolutions annoncées pour 2025-2026 portent davantage sur l’intégration avec Microsoft 365 Defender que sur la granularité géographique du diagnostic réseau.
Les outils DEX ne font-ils pas déjà le travail d’observabilité Teams ?
Les plateformes DEX mesurent l’expérience applicative globale sur le poste utilisateur — temps de démarrage, score de santé du device, latence applicative. Elles ne descendent pas au niveau du codec audio/vidéo spécifique à Teams, ni ne corrèlent les adaptations de qualité avec l’état d’un point d’accès WiFi ou d’un routeur de site. Les deux approches sont complémentaires, pas substituables.
Comment justifier l’investissement dans une solution d’observabilité Teams auprès de la direction ?
L’argument le plus solide porte sur le coût évité : sans visibilité technique précise, les équipes IT procèdent à des remplacements matériels non ciblés (switches, points d’accès WiFi, routeurs) sans garantie que le problème sera résolu. L’observabilité granulaire permet d’identifier l’équipement défaillant avant d’engager le budget, transformant une dépense subie en investissement maîtrisé. Les données de l’ARCEP — 78% des incidents liés à des congestions réseau locales — constituent également un appui factuel pour étayer ce type de décision.
Quelle est la différence entre observabilité réseau et monitoring réseau pour Teams ?
Le monitoring mesure des métriques prédéfinies (disponibilité, seuils d’alerte). L’observabilité va plus loin : elle permet d’explorer des états système non anticipés en corrélant des sources de données hétérogènes — métriques réseau locales, données codec Teams, comportement applicatif. Pour un incident Teams intermittent sur un site spécifique, c’est cette capacité d’exploration qui fait la différence entre un diagnostic en 20 minutes et une investigation de plusieurs jours.
Ce qu’il faut retenir pour la suite
La qualité des appels Teams est un indicateur indirect de santé de l’infrastructure réseau locale. Traiter les tickets comme des problèmes applicatifs isolés, sans remonter jusqu’aux métriques du segment réseau concerné, revient à soigner le symptôme sans toucher à la cause. Les données disponibles — 78% de congestions locales selon l’ARCEP, 63% d’incidents de configuration locale selon l’ANSSI — pointent dans la même direction.
- Auditez votre outil de monitoring actuel : peut-il isoler les métriques réseau par site géographique, pas seulement par tenant ?
- Vérifiez la disponibilité des données codec (latence RTP, MOS, gigue) dans votre stack de monitoring actuel pour les sessions Teams.
- Évaluez le délai de disponibilité des données : un outil avec un délai supérieur à 5 minutes rend le diagnostic en temps réel impossible sur incidents intermittents.
- Documentez vos trois derniers tickets Teams non résolus : identifiez si l’absence de granularité géographique ou de corrélation codec en était la cause principale.
- Consultez les recommandations du W3C sur l’observabilité WebRTC pour cadrer les exigences techniques d’une solution adaptée à votre contexte multisites.
La question qui structure les prochaines décisions d’infrastructure n’est plus « quel outil de monitoring utiliser ? » mais « quelle granularité de données est nécessaire pour diagnostiquer sans tâtonner ? ». Répondre à cette question avec des données précises, c’est aussi ce qui permet aux équipes IT de justifier leurs investissements en outils de productivité digitale auprès des directions métier.